Jon Udell运用ChatGPT、Cody以及GitHub Copilot来协助他为Steampipe开发ODBC插件,后者是一个可扩展的SQL接口,用以连接云API。
译自 How LLMs Helped Me Build an ODBC Plugin for Steampipe 。
我在LLM时代来临前已经为我的前两款Steampipe插件(Hypothesis和Mastodon)编写了代码,因此非常渴望能与我的助手团队一起开发下一个项目:用于ODBC(开放数据库连接)的插件。
Steampipe从表面上是将API映射到数据库表。当你执行select * from aws_sns_topic时,Steampipe实际调用的是AWS ListTopics API。许多Steampipe插件就是这样工作的:一个表对应一个特定的API调用。
但是,有些插件工作方式更为通用。Net插件中的net_http_request表将Steampipe变成了HTTP客户端。exec插件为shell命令创造了SQL接口,Terraform插件对基础设施即代码配置文件也做了同样的工作。通过扩大什么才算API的定义,Steampipe不断拓展它对各种形式结构化数据的支持。
数据库也提供了一种API。Steampipe的数据库插件不能使用固定模式,而必须动态发现模式。当插件SDK增加对动态模式的支持时,CSV插件第一个使用了这个特性。因此,它成为启发ODBC插件的一个来源,后者会为任何具有ODBC驱动的数据库创建SQL接口。
Jose Reyes的Postgres插件是另一个灵感来源(清楚起见,这只是他对Steampipe的深入研究的一小部分)。Postgres插件使Steampipe可以查询远程Postgres表。
这是我的梦想。嘿,问问又不会受伤,对吧?但这对我的团队来说不是很好的使用方式。我无法让ChatGPT、Sourcegraph Cody或GitHub Copilot从例子中推断出任何接近工作插件的东西。相反,像往常一样,我们将任务分解成可管理的块。像往常一样,这样效果很好。
这里有一个小例子,说明了它提供的有用帮助。该插件需要一个配置文件来定义ODBC数据源和表名。这些定义使用HCL编写。通过团队的反复讨论,我设计了一种格式,可以与Steampipe的配置模式一起使用。
connection "odbc" {
plugin = "odbc"
data_sources = [
"SQLite:foo",
"PostgreSQL:jose"
]
}
给定这一点,LLM然后就可以编写插件配置所需的样板代码了。这些小事积少成多。
unixODBC的驱动程序管理器,然后添加可以连接SQLite或Postgres的驱动程序,或者连接那些甚至不是数据库的源(它们是进入其他数据源宇宙的门户)。CData提供了广泛的ODBC驱动程序,其中一些与Steampipe插件重叠,而其他则没有。这听起来是测试插件的一个有趣第一步,因此我安装了CData的RSS和Slack驱动程序,并着手让插件发现它们的模式。
但是,当我试图在插件的初始化阶段调用ODBC驱动程序时,没有任何作用;日志中还出现了关于底层操作系统信号处理的不祥信息。这是我无法调试的问题——是Steampipe?CData?unixODBC?还是三者的组合?但如果可能的话,我仍想取得进展。因此,我尝试了几种解决方案:使用互斥锁保护插件对ODBC驱动程序的调用,调整时序,以及最终有效的在初始化后运行模式发现并将模式缓存到文件系统。ChatGPT说这“有点投机取巧”。但我能够快速迭代这些选择的能力,在其帮助下,起到了决定性作用。
分配给你的未关闭问题。
select
repository_full_name,
number
title
from
github_my_issue
where
state = 'OPEN';
select
repository_full_name,
number
title
from
github_my_issue
where
state = 'OPEN';
如果GitHub插件不实现下推,Steampipe会将查询映射到GitHub API来列出所有你的问题,并返回包含所有问题的表。然后Steampipe的Postgres引擎会将WHERE条件应用到结果过滤,只保留打开的问题。
当然,你更希望在可能的情况下将此类过滤下推到API中。因此,这里实际发生的是插件将state定义为可选的键列(也称为限定词或“qual”)。当查询包含where state = 'OPEN'时,插件会调整API调用以包含该过滤条件。
当插件的API是SQL时,同样的想法也适用。你可以在这里的Postgres插件中看到。表定义的List函数将在每个发现的模式中将所有列设置为可选的键列,以便在Steampipe的WHERE子句中提及它们中的任何一个或全部,并下推到远程Postgres处理的WHERE子句中。
ODBC插件也是如此。仅从这个查询中你无法看出来。
select
name,
number,
_metadata
from
odbc.sqlite_foo
where
number = 1
+------+--------+-------------------------------------------+
| name | number | _metadata |
+------+--------+-------------------------------------------+
| jon | 1 | {"connection_name":"odbc","dsn":"sqlite"} |
+------+--------+-------------------------------------------+
但是在内部,因为插件实现了下推,其调试日志显示WHERE过滤器是由SQLite处理的,而不是由Steampipe处理。
ChatGPT在第一次试验中没有做对。尽管Postgres插件提供了清晰的例子,但它提供的部分解决方案正确地调整了传递给SQLite的SQL,却忽略了定义可选键列这一点。这很容易修复,最终我们一起实现了这个功能,比我自己工作轻松许多。
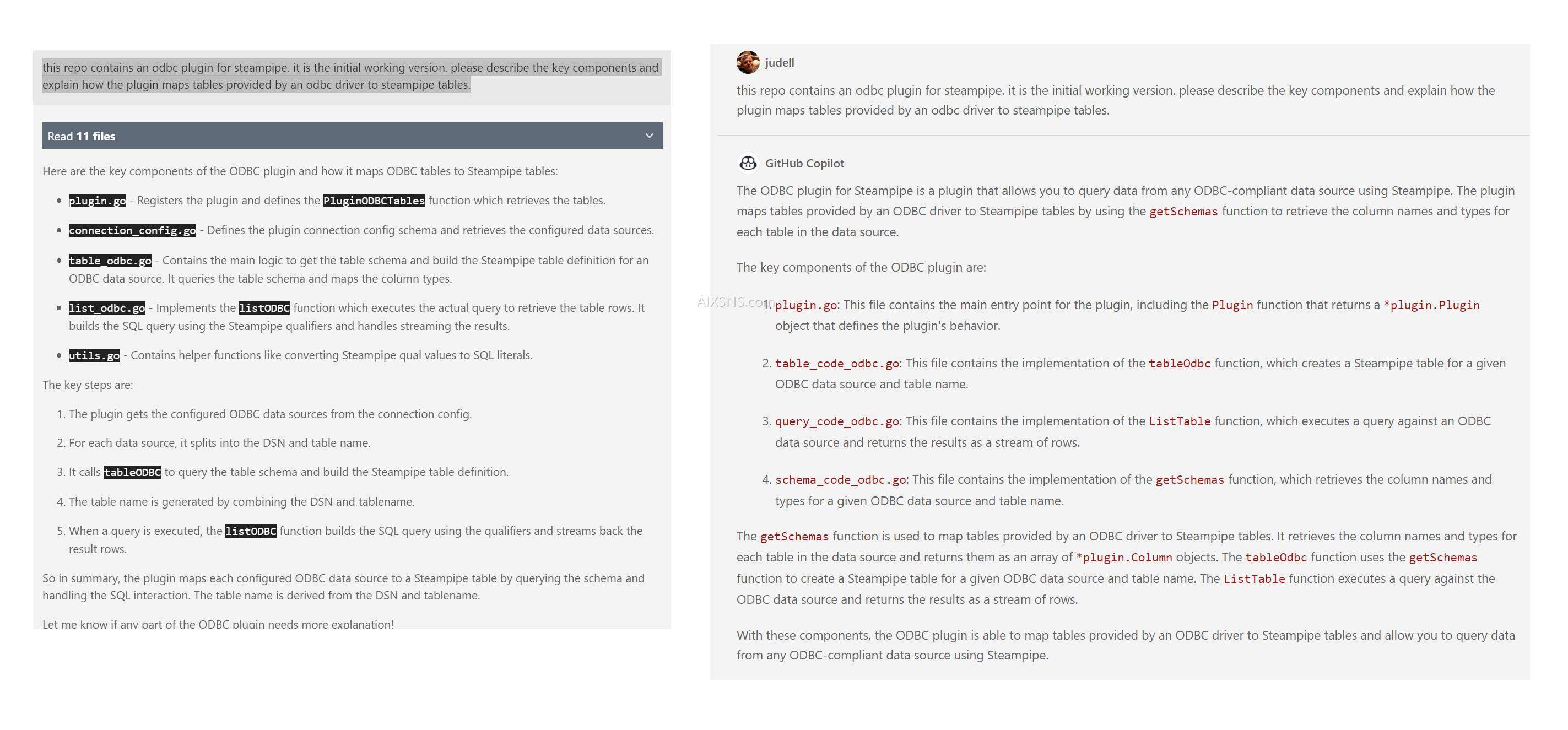
然后我要求Cody和Copilot评估模式发现策略。我已经与ChatGPT进行了广泛讨论,并认为明显的缺陷——对第一行采样的风险可能会对某些列找到空值——对首个版本的插件来说是一个可以接受的风险,该插件可能会在以后用特定于数据库的逻辑进行增强。
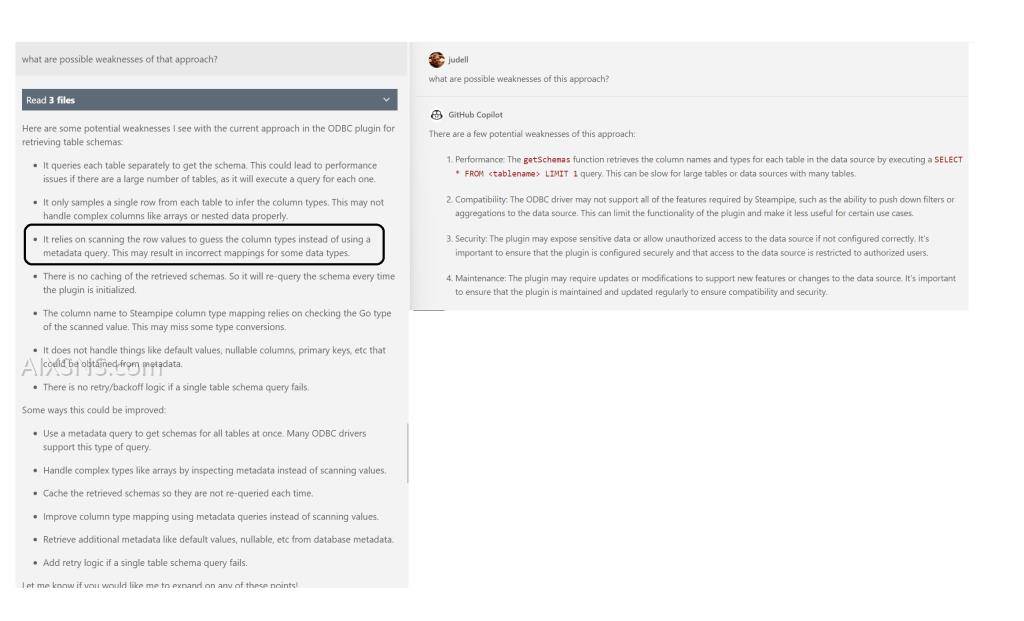
Cody对关键缺陷的更完整和连贯的回应证实了这一点,而Copilot较短的回答则忽略了这点。
总的来说,我发现请LLM回顾代码和文字都很有帮助。当橡皮鸭回话时,反馈可能有用也可能无用,不准确。但无论哪种方式,这种互动都可以促使你以不同的视角思考你正在做的事情。这感觉上具有内在价值。
