
上图红色圈中的部分为 Multi-Head Attention,是由多个Self-Attention组成的,虽然Encoder与Decoder中都有Multi-Head Attention,但他们略有区别。Encoder block包含一个 Multi-Head Attention, 而Decoder block包含两个 Multi-Head Attention。
Decoder block包含两个 Multi-Head Attention,其中第一层的多头注意力用到Masked,第二层其数据组成则是由 Encoder输出数据的3/4直接送入( Encoder输出的另外1/4数据入了Add&Norm层) 再加上 由Decoder的Outputs进入的经Token Embedding和Position Enbedding计算后得的向量,经过第一层多头注意力后的数据
注意力
Attention函数可以描述为将query和一组key-value对映射到输出,其中query、key、value和输出都是向量。 输出为value的加权和,其中分配给每个value的权重通过query与相应key的兼容函数来计算。
—— 来自(www.yiyibooks.cn/yiyibooks/A…)
QKV的理解
在《Attention is all you need》论文中首次提出Transformer时构建了三个辅助向量QKV。而所谓QKV也就是Q(Query 查询),K(Key 键值),V(Value 实际的特征信息)。 他们本质上是代表了三个独立的矩阵,都是我们原本的序列X做了不同的线性变换之后的结果,都可以作为X的代表。简单的可理解成:
Q=XWQK=XWKV=XWVQ = XW^Q \
K = XW^K \
V = XW^V \
如下图所示:

其中 WQ,WK和WVW^Q,W^K和W^V是三个可训练的参数矩阵,输入矩阵X分别与WQ,WK和WVW^Q,W^K和W^V相乘,生成Q, K和V, 相当于经历了一次线性变换。Attention不直接使用X,而是使用经过矩阵乘法生成的三个矩阵,因为使用三个可训练的参数矩阵,可增强模型的拟合能力。
多头注意力
什么是多头注意力
所谓多头,是分别将线性的变换之后的QKV切分为H份,然后对每一份进行后续的self-attention操作。最后再连接并做线性回归产生输出。如下图:
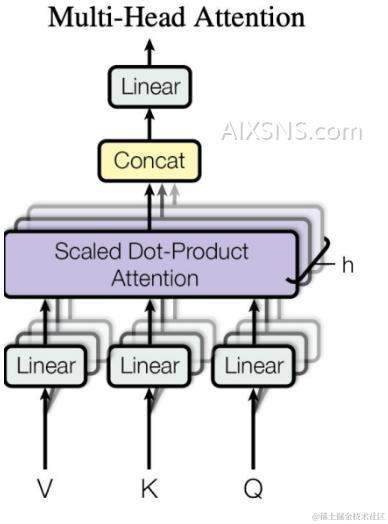
观察上图的多头注意力结构的中间的Scaled Dot-Product Attention(点积自注意力),我们可以把拆为理解为高维向量被拆分为H分低维向量,并在H个低维空间里求解各自的self-Attention。
多头注意力的理解
- 代码层面: 把原始的维度切成H份,假如h=8(切成8份),每份则为512/8=64。在每个64维做相关度(即相乘)计算
- 原理层面: 把原来在一个高维空间里衡量一个文本的任意两个字之间的相关度,变成了在8维空间里去分别衡量任意两个字的相关度的变化
工作原理
QKV获取
经过position embedding 与 word embedding 计算后得到的向量x进入Encoder,经过3次线性变化之后,得到QKV,如下图:
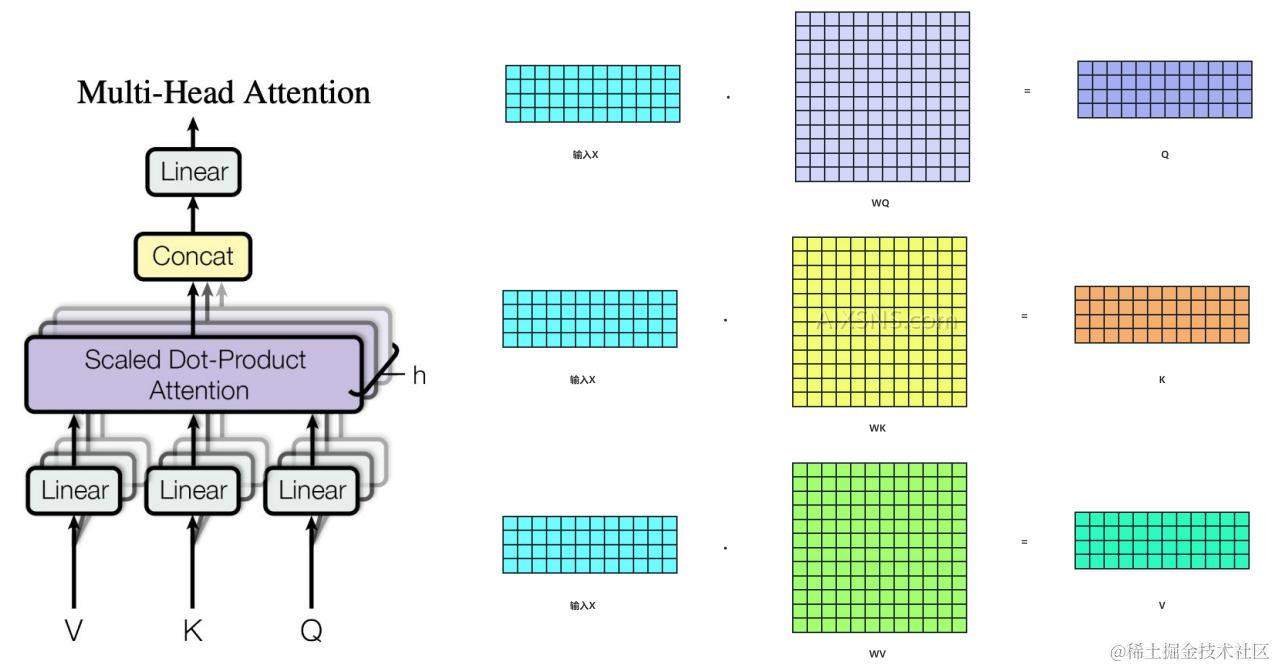
获取每个字都形成512/H维度的信息
一个完整的数据矩阵, 经过计算得到QKV之后,分别获取三个(batch_size)维向量矩阵(下图右侧第一列),再次水平切分矩阵为(seq_len * 512维的信息) 数据(如下图右侧第二列)按,按字按维度切成H份(如最右侧的第三列)。再然后,计算一个字的维度。即将一个字分成H分,每一份为512/H维信息,那么一个完整的字一共有512/H维度的信息(transformer中h=8)。

在H维空间中矩阵拆变如下:
[batch-size、seq-len、dim]
[batch_size, seq_len, h, dim/h]
---举例---
[1024, 5, 512 ]
[1024, 5, 8, 512/8]
在H个子维度里计算任意两个字的盯关度
每个字的第1头和其他字的第一头分别相乘
比如 “我“ 字,按h=8拆分,得64(512/8) 维的信息。接下来再把我字的第一个64维度的信息分别和其他字的第一个64维的信息进行向量相乘。如果相乘的结果越大代表两个向量相似度接高,越小两个向量的相似度越低。如下图,右侧说明一个序列的第1个字的64维分别与其他字的第一个64维的向量相乘(对于我要吃汉堡,一共是5个字,对应右侧的5个图,从左到向,从上一下:我 想 吃 汉 堡)。

在H个不同的(512/H)维计算相关度
经过上图的拆分,由原来在512的大的维度空间里计算相似度,变成了在H个不同的(512/H) 维的子空间里分别去计算任意两个字的相似(关)度。
比如:原来只进行1次的512 * 512的向量相乘 现在变成进行8次的64 * 64这样的向量相乘,即把原来的高维空间映射成了8个不同的64维的子空间,在每字64维的子空间里,分别去衡量这一序列字词之任意两个字之间的相似度,进而提升模型的表达能力。
再进行组合成为一个512维的矩阵
当拆分计算完成即相乘之后,再连接并做线性回归产生输出, 形成如下右图所示的矩阵,第一个格子的相似关是Q∗KtQ* Kt,其他格子也是…即再聚合起来(线性变化)成为一个512维的矩阵。

多头注意力公式
MultiHead(Q,K,V)=Concat(head1,…,headh)∗WO其中headi=Attention(QWiQ,KWiK,VWiV,)MultiHead(Q,K,V) = Concat(head_1,…,head_h)*W^O \
其中 head_i = Attention(QW_i^Q,KW_i^K,VW_i^V,)
其中参数映射为矩阵:
WiQεRdmodel∗dk,WiKεRdmodel∗dk,WiVεRdmodel∗dv,WOεRdmodel∗hdvW_i^Q ε R^{d_{model} * d_k}, W_i^K ε R^{d_{model} * d_k}, W_i^V ε R^{d_{model} * d_v}, W^O ε R^{d_{model} * hd_v}
transform: h=8,dmodel=512,dk=dv=dmodel/h=512/8=64h=8,d_model=512, d_k=d_v=d_{model}/h = 512/8 = 64
自注意力-Self-Attention
从多头注意力的结构可以看到由H份组成的”Scaled Dot-Product Attention”,称为点积注意力层 或 自注意力(self-attention)。输入由query、dk 维的key和dv维的value的组成,用dk相除query、d_k 维的key和d_v维的value的组成,用sqrt{d_k}相除,然后应用一个softmax函数以获得值的权重。
结构如下:

上图是 Self-Attention 的结构,在计算的时候需要用到矩阵QKV。其中,Self-Attention接收的是输向量x组成的矩阵X,或者上一个Encoder block的输出。经过三次线性变化得到的QKV。
Q与KtK^t经过MatMul,生成相似度矩阵。对相似度矩阵每个元素除以 dksqrt{d_k} ,其中dkd_k为K的维度大小。这个除法被称为Scale。 当dkd_k很大时,Q*KTK^T的乘法结果方法变大, 进行Scale可使方差变小,训练时梯度更新更稳定。
Mask是个要选环节,在机器翻译等自然语言处理任务中经常使用的环节。在机器翻译等NLP场景中,每个样本句子的长短不同,对于句子结束之后的位置,无需参与相似度的计算,否则影响Softmax的计算结果。
softmax是个激活函数,在没有Mask时,softmax只起到归一化的作用。
自注意力机制将一个单词与句子中的所有单词联系起来,从而提取每个词的更多信息。
注意力公式
Attention(Q,K,V)=softmax(QKTdk)∗Vdk是Q,K矩阵的列数,即向量维度Attention(Q,K,V) = softmax(frac{QK^T}{sqrt{d_k}})*V
\
d_k是Q,K矩阵的列数,即向量维度
其中,Q为Query、K为Key、V为Value。QKV都是从同样的输入矩阵X经过三次线性变换而来的。
1dkfrac{1}{sqrt{d_k}}: transformer采用了点积(乘法)attention,在此基础上增加了缩放因子1dkfrac{1}{sqrt{d_k}}。
对于很大的dkd_k值,点积大幅度增长,将softmax函数推向具有极小梯度的区域[4]。 为了抵消这种影响,在点积(乘法)attention算法上增加了缩放因子1dkfrac{1}{sqrt{d_k}}
公式推导
先计算softwax,输入为词向量矩阵X,经过与三个系数 WQ,WKW^Q,W^K和WVW^V 进行矩阵乘法,首先生成Q、K和V。 如下图:

用Softmax计算每个单词对其他单词的attention系数: 得到QKTQK^T之后,使用Softmax计算每一个单词对于其他单词的attention系数,公式中的Softmax是对矩阵的每一行进行Softmax。
输出Attention(Q,K,V): 得到Softmax矩阵之后和V相乘,得到最终的输出Attention(Q,K,V) 。如下图:

Attention(Q,K,V)=softmax(QKTdk)∗VAttention(Q,K,V) = softmax(frac{QK^T}{sqrt{d_k}})*V
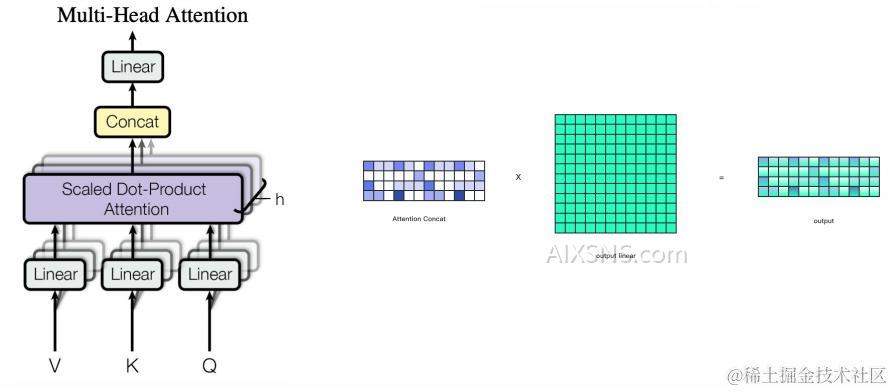
PS: 最后再经过一个Concat(聚合)再经过Linear(线性变换) ,得到最后的整个多头注意力机制的输出。如下
笔记写于:2023年11月07日凌晨
最后修订:2023年11月10日
1.文章和论文有些地方有出入,看论文译文修改,很是抱歉。
2.有些错字字
3.加上了参考文章的链接
[参考]
www.yiyibooks.cn/yiyibooks/A…
luweikxy.gitbook.io/machine-lea…
