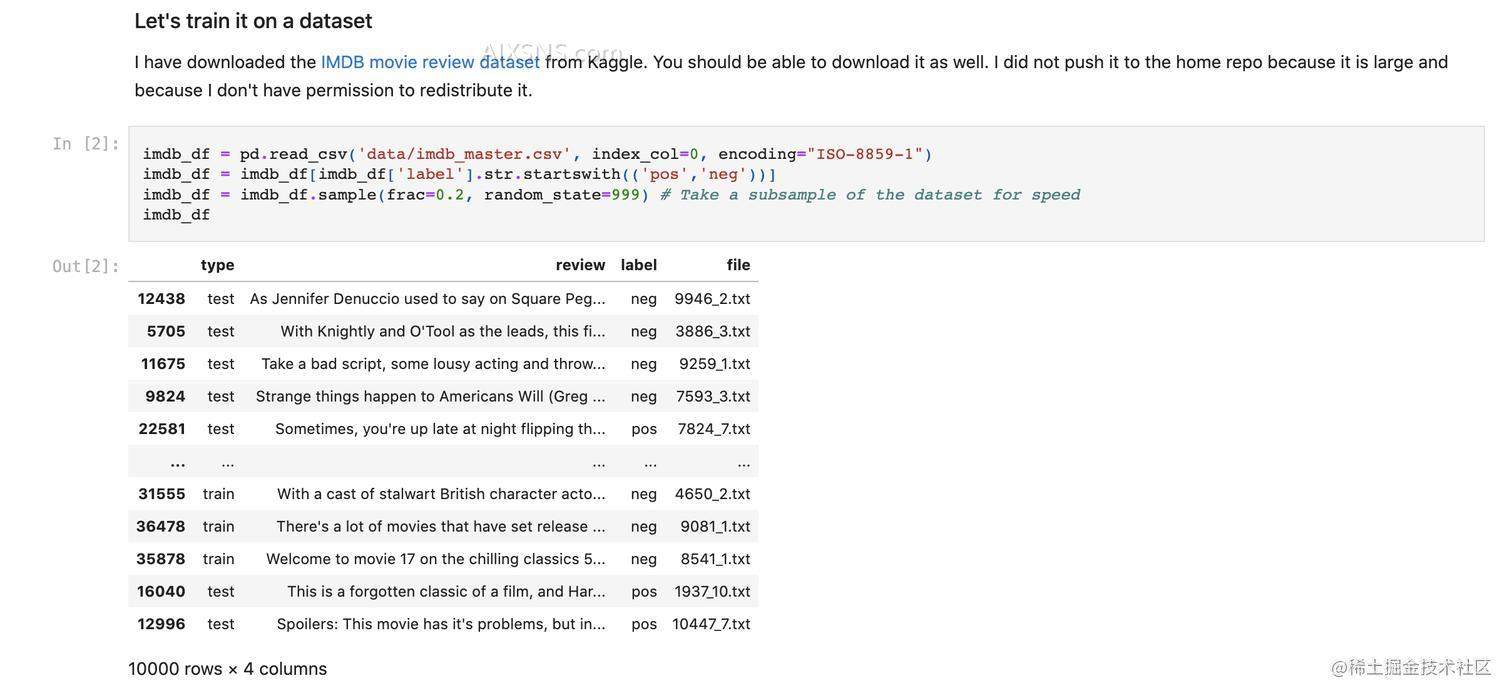
本次课讲师用了IMDB电影评论数据,我们需要根据review字段(文本)预测该评论是positive还是negative的评论,所以需要先想办法将文本转换为可用的数字格式,本例中使用了sklearn中CountVectorizer
注意: test data一定是从来没有被用过的数据,这样才能模拟模型部署后的场景(模型部署后,会用在从未见过的数据上对其进行预测),所以本例中一定要小心,要先对数据进行train test split之后,再使用train set 和CountVectorizer构建文本Vocabulary。 反之,如果先用CountVectorizer对整体数据进行fit_transform,再对形成的数值数据进行train_test_split,就违反了test data没被用过的原则(unseen, fresh)
This is called The
Golden Rule of ML: the test data should not influence the training process in any way. If we violate the Golden Rule, our test score will be overly optimistic!
A test set should only be used “once”.
Even if only used once, it won’t be a perfect representation of deployment error:
- Bad luck (which gets worse if it’s a smaller set of data)
- The deployment data comes from a different distribution
- And if it’s used more than once, then you have another problem, which is that it influenced training and is no longer “unseen data”
背景

数据
CountVectorizer 用法
# How about this: each word is a feature (column), and we check whether the word is present or absent in the review 💡
from sklearn.feature_extraction.text import CountVectorizer
# vec = CountVectorizer(min_df=50, binary=True) # words that appear at least n times
vec = CountVectorizer(max_features=1000, binary=True) # max n columns
# For feature preprocessing objects, called transformers,
# we use `transform` instead of `predict` (indeed, it's not a prediction),
# there is shorthand for this in scikit-learn:
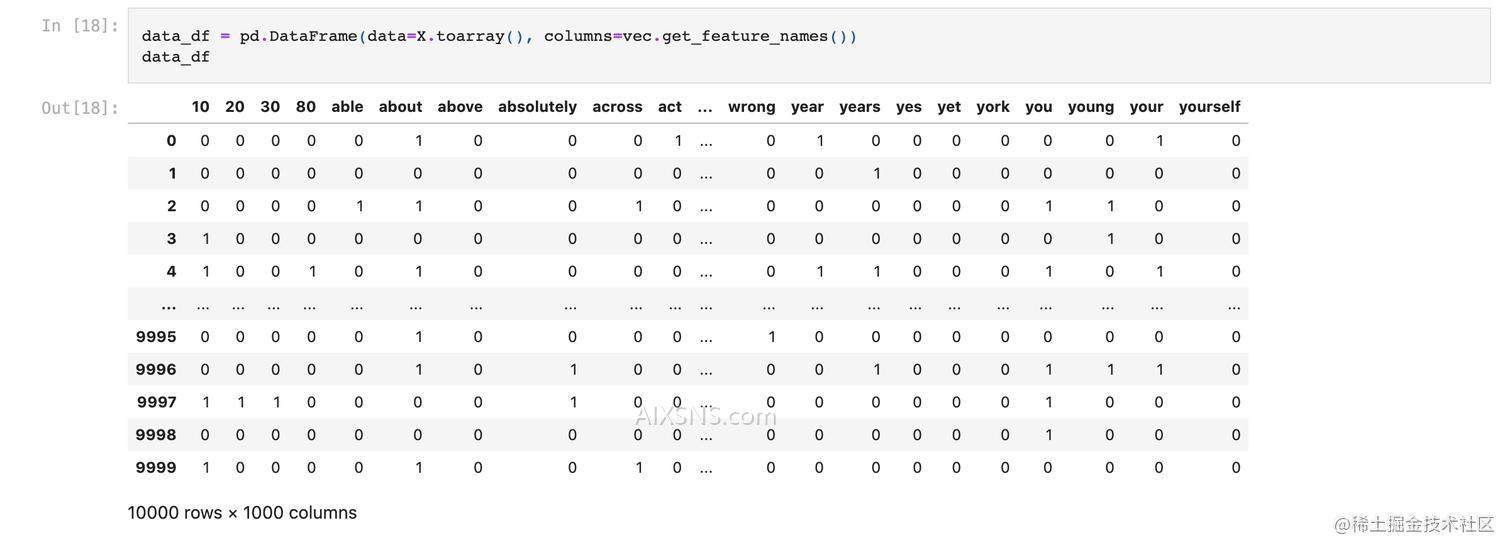
X = vec.fit_transform(imdb_df["review"])
# vec.get_feature_names() 可以查看vocabulary
data_df = pd.DataFrame(data=X.toarray(), columns=vec.get_feature_names())
data_df
data_df如下:
完整代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.size'] = 16
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
# 准备数据,只拿20%做演示,为了运行速度
imdb_df = pd.read_csv('data/imdb_master.csv', index_col=0, encoding="ISO-8859-1")
imdb_df = imdb_df[imdb_df['label'].str.startswith(('pos','neg'))]
imdb_df = imdb_df.sample(frac=0.2, random_state=999)
# STEP 1, 一开始就准备好test data,为了满足golden rule
imdb_train, imdb_test = train_test_split(imdb_df, random_state=123)
# 只考虑review字段来做分类
X_train_imdb_raw = imdb_train['review']
y_train_imdb = imdb_train['label']
X_test_imdb_raw = imdb_test['review']
y_test_imdb = imdb_test['label']
vec = CountVectorizer(min_df=50, binary=True)
X_train_imdb = vec.fit_transform(X_train_imdb_raw)
# We transform the test data with the transformer *fit on the training data*!!
X_test_imdb = vec.transform(X_test_imdb_raw)
# Ok, let's give this a try, you can always use DummyClassifier in sklearn to get a baseline
# here we use DecionTree from the last lecture
# from sklearn.dummy import DummyClassifier
# dc = DummyClassifier(strategy="prior")
# dc.fit(X_train_imdb, y_train_imdb)
# dc.score(X_train_imdb, y_train_imdb) # 0.5024
dt = DecisionTreeClassifier()
dt.fit(X_train_imdb, y_train_imdb)
dt.score(X_train_imdb, y_train_imdb) # 1.0
dt.score(X_test_imdb, y_test_imdb) # 0.686, 可以看到 DT在此处有overfitting迹象
lr = LogisticRegression(max_iter=1000)
lr.fit(X_train_imdb, y_train_imdb)
lr.score(X_train_imdb, y_train_imdb) # 0.9833333333333333
lr.score(X_test_imdb, y_test_imdb) # 0.8256, Cool, we got a better test error this way!
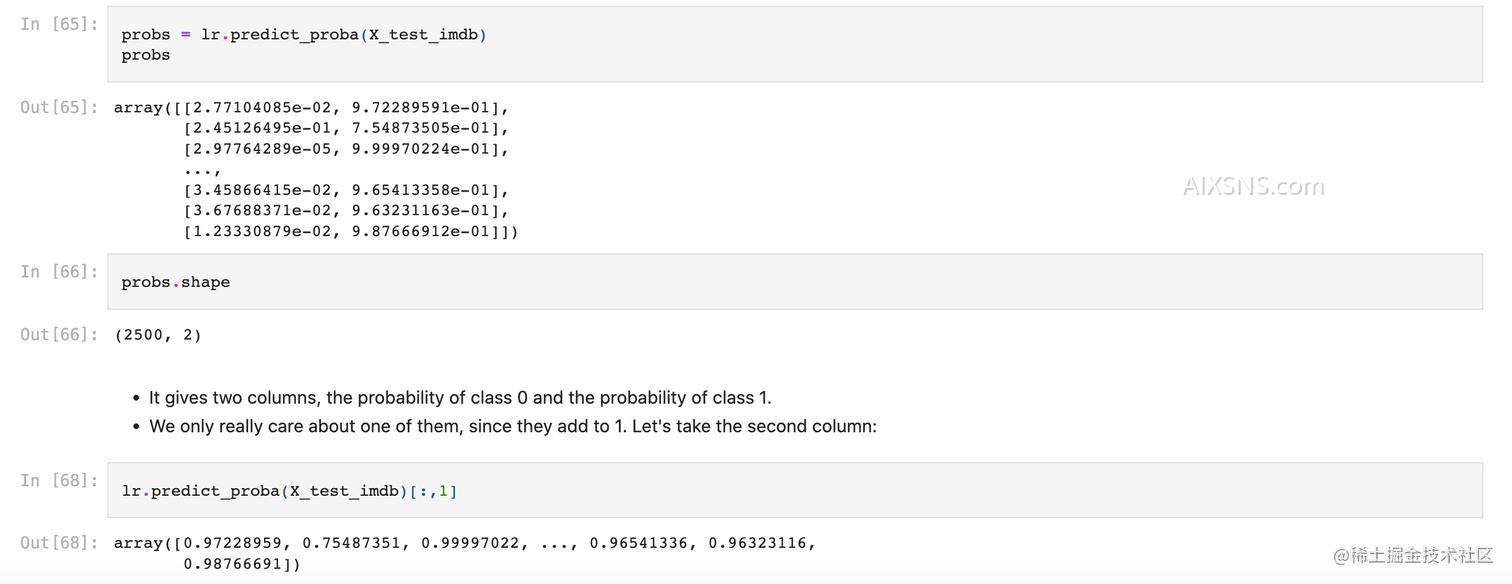
lr.classes_ # array(['neg', 'pos'], dtype=object)
predict_proba: useful confidence scores, but we won't interpret them as actual probabilities,不能完全理解为概率
Logistic regression: coefficients and interpretation
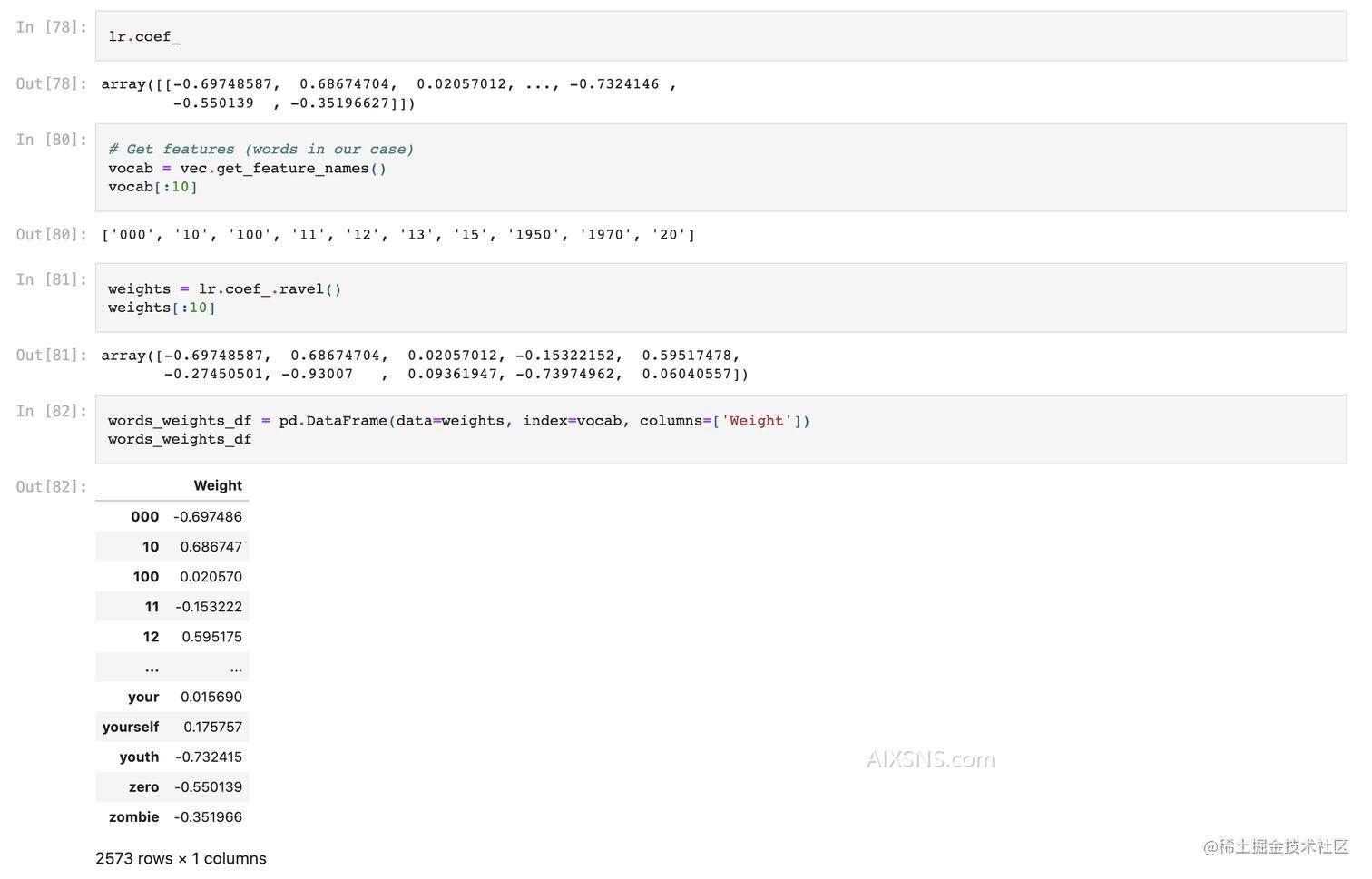
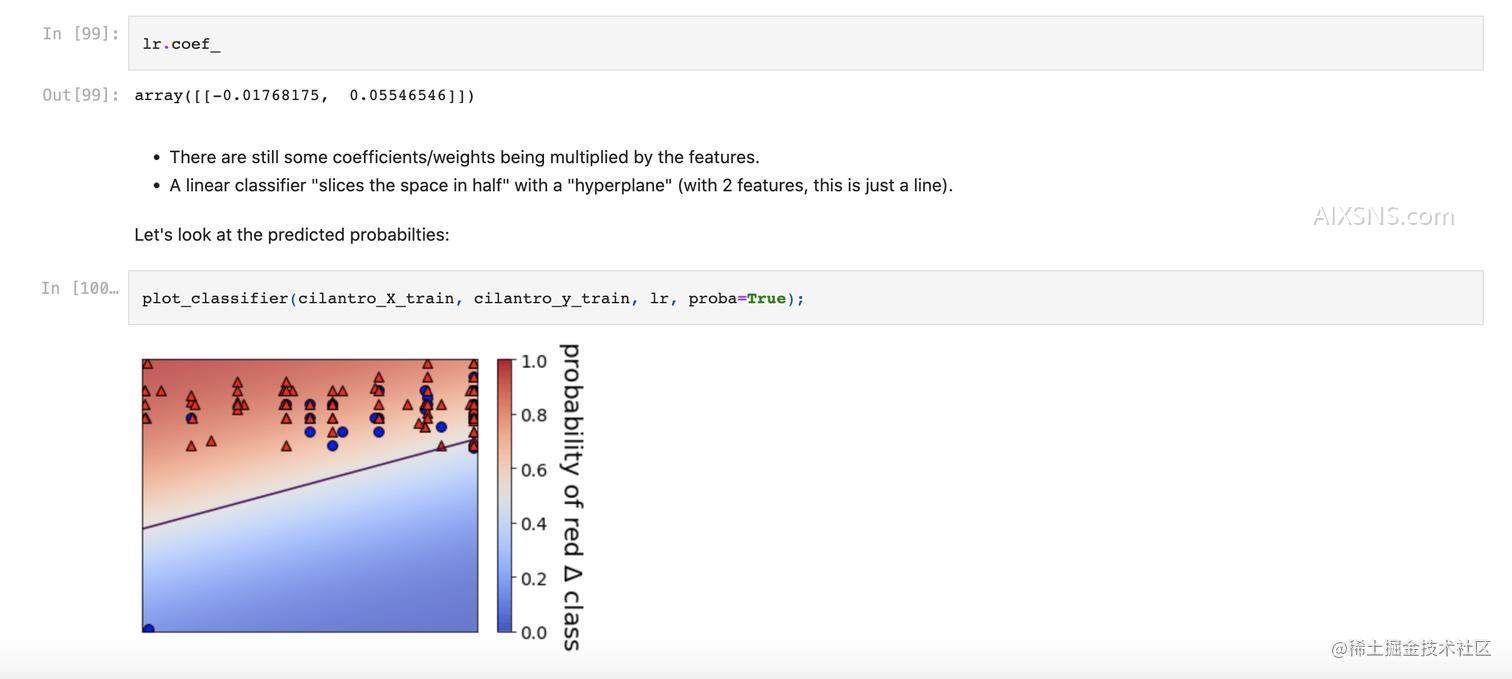
- One of the primary advantage of linear classifiers is their ability to interpret models.
- What features are most useful for prediction? What words are swaying it positive or negative?
- The sign matters: positive means increasing that feature gives a higher probability score for the “positive class” (arbitrarily defined for each problem)
- The magnitude matters: larger coefficients means the feature contributes more toward the scores
Let’s find the most informative words for positive and negative reviews
- The information you need is exposed by the
coef_attribute of LogisticRegression object. - The vocabulary (mapping from feature indices to actual words) can be obtained as follows:
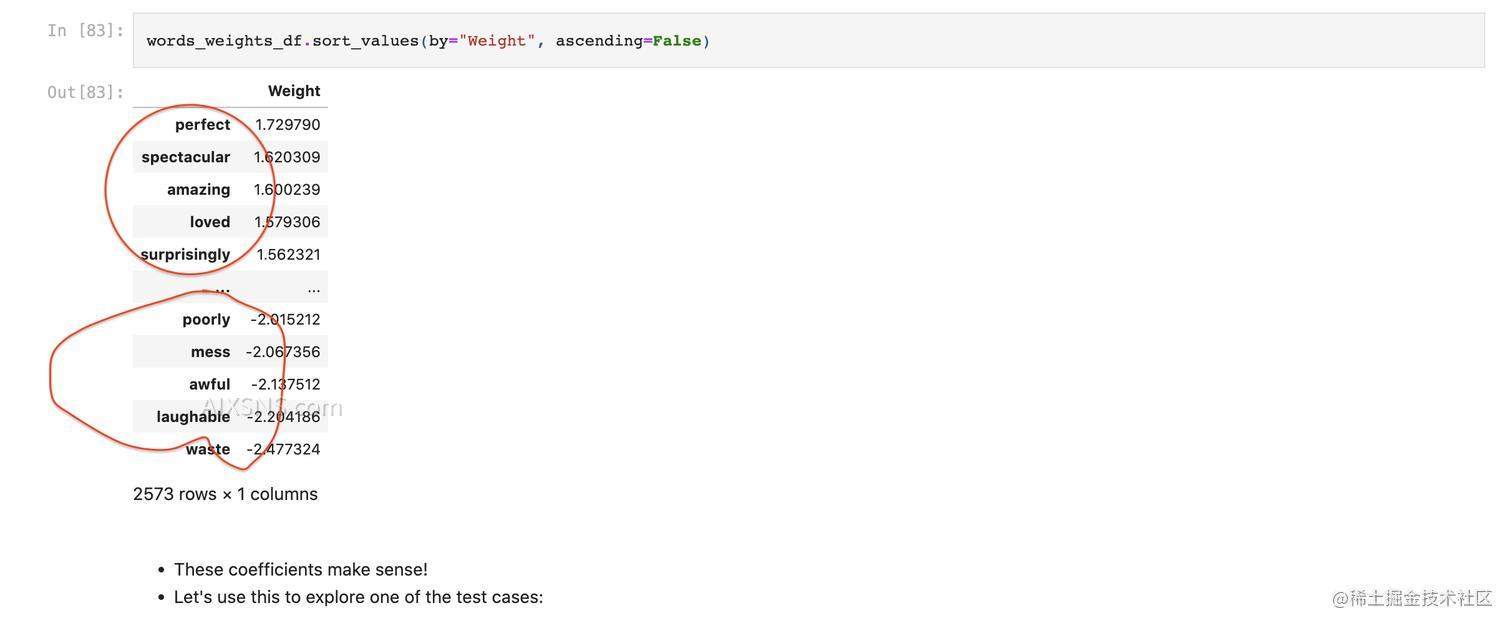
总结
Why people use logistic regression, LR的优点?
-
Logistic regression is extremely popular!
-
Fast training and testing.
- 意味着可以 Training on huge datasets.
-
Interpretability
- Weights are how much a given feature changes the prediction and in what direction.
LR的decision boundary 决策边界
LR的决策边界是 hyperplane
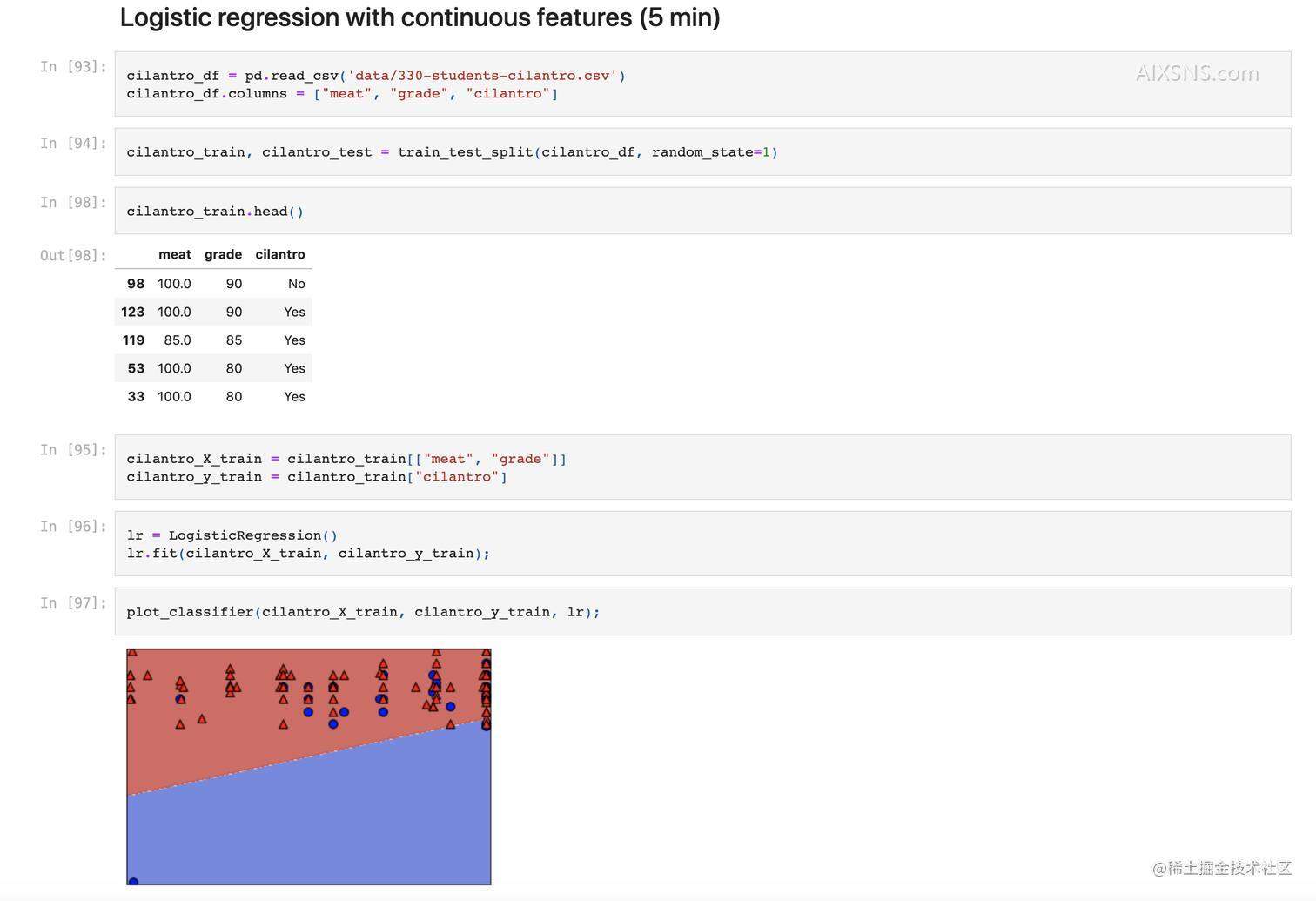
此处以第一课收集的 330-students-cilantro.csv(一个人造的数据,利用问卷调查问每个学生的有多喜欢吃肉以及他的考试得分来预测其是否喜欢香菜,很没有说服力的特征,讲师只是为了演示)
LR中重要的超参数C
An important hyperparameter: C (default is C=1.0).
- In general, we say smaller
Cleads to a less complex model (like a shallower decision tree).- Complex models are really a larger
Cin conjunction with lots of features. - Here we only have 2 features.
- Complex models are really a larger
超参数C不能是负数,关于C的具体原理,会在课程 CPSC340中解释
参考
[1] www.youtube.com/watch?v=7-n…
