注:
- 本文是基于吴恩达《LangChain for LLM Application Development》课程的学习笔记;
- 完整的课程内容以及示例代码/Jupyter笔记见:LangChain-for-LLM-Application-Development;
课程大纲
此主要包括两部:
- 直接使用 OpenAI API 接口进行调用,直观感受下其 API 的使用方式以及存在的问题;
- 使用 LangChain 的 API 对上述问题进行优化,主要包括 3 个方面:
- Prompts:提示词,期望语言模型返回的内容。也就是我们通常理解的问题;
- Models:模型,是指支撑大部分工作的语言模型;
- Output parsers:返回数据解析,是指将语言模型的返回的结构化信息(JSON)进一步处理分发;
其中 LangChain 部分的主要内容如下图:
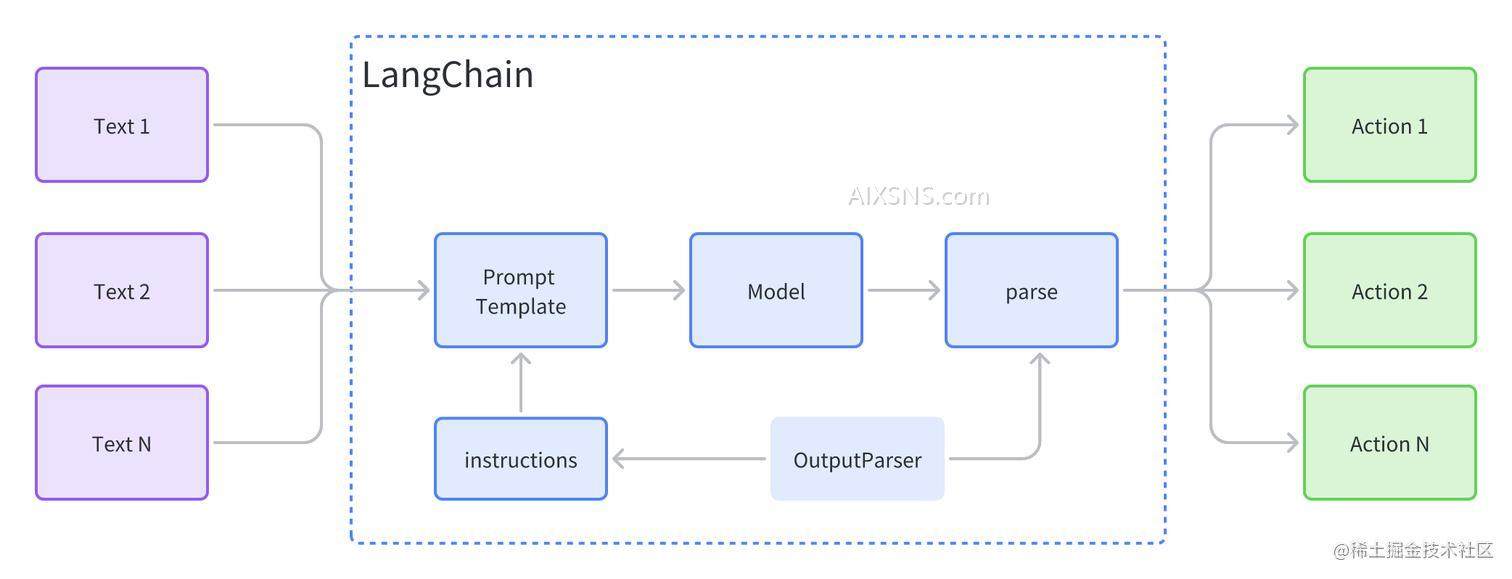
直接使用 OpenAI API 完成一个 LLM 应用的开发,会存在很多的胶水代码,而 LangChain 就是提供的一种很好的方式来处理上述的一些问题。
获取 OpenAI API Key
在开始之前请确保你已经有 OpenAI API Key 了,这个是访问 OpenAI API 接口的凭证,也是通过这个 Key 来进行计费的。
将 API Key 设置到系统的环境变量之后,就可以安装 OpenAI 提供的 Python SDK 了。通过 os.environ['OPENAI_API_KEY'] 获取系统遍历中设置的 key,让后将其设置到 SDK 中。
注:这里是最佳实践,这种方式可以在多个项目中使用相同的 key,同时不用将 key 记录到版本控制中。当然,你也可以直接将 key 写死在代码中。
# 安装对应的依赖
%pip install python-dotenv
%pip install openai
import os
import openai
# 设置 API Key
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']
OpenAI : Chat API
下面我们就开始看一下 OpenAI 对话的接口是如何使用的。首先定义一个对话函数 get_completion(),然后使用这个函数开始一个简单的对话。
# 定义函数,封装 OpenAI SDK 的一些基本参数
def get_completion(prompt, model="gpt-3.5-turbo"):
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0,
)
return response.choices[0].message["content"]
# 询问问题:What is 1+1?
get_completion("What is 1+1?")
'As an AI language model, I can tell you that the answer to 1+1 is 2.'
复杂 Prompt
上面 1+1 等于几的问题非常简单,在正式的项目开发中使用场景往往会更加复杂。我们以收到用户反馈邮件场景为例看一下 OpenAI 的 SDK 应该如何使用。
场景是你在一个国际化的公司,经常会收到一些不同国家用户的邮件反馈,同时用户遇到问题时情绪可能是比较激烈的。所以我们的 Prompt 需要做两件事情:
- 将不同的语种翻译成中文,方便阅读;
- 将邮件中的语气进行调整, 使其更加平静友好(这样容易开展工作😜);
我们编写的 Prompt 中首先会有用户的邮件内容,同时为了扩展性我们把邮件的语气也提取出来,方便将内容根据不同的场景扩展成不同的风格。
下面是一些具体的代码细节:
# 用户的原始邮件内容
customer_email = """
Arrr, I be fuming that me blender lid
flew off and splattered me kitchen walls
with smoothie! And to make matters worse,
the warranty don't cover the cost of
cleaning up me kitchen. I need yer help
right now, matey!
"""
# 转录邮件的语气风格
style = """Simplified Chinese, in a calm/friendly/formal/respectful tone"""
prompt = f"""Translate the text
that is delimited by triple backticks
into a style that is {style}.
text: ```{customer_email}```
"""
print(prompt)
日志输出为:
Translate the text that is delimited by triple backticks
into a style that is Simplified Chinese, in a calm/friendly/formal/respectful tone.
text: “` Arrr, I be fuming that me blender lid flew off and splattered me kitchen walls with smoothie! And to make matters worse,the warranty don’t cover the cost of cleaning up me kitchen. I need yer help right now, matey!
`
Translate the text that is delimited by triple backticks
into a style that is Simplified Chinese, in a calm/friendly/formal/respectful tone.
text: ```
Arrr, I be fuming that me blender lid flew off and splattered me kitchen walls with smoothie! And to make matters worse,the warranty don't cover the cost of cleaning up me kitchen. I need yer help right now, matey!
```
请求接口:
response = get_completion(prompt)
print(response)
嗯,我很生气,我的搅拌机盖飞了出去,把我的厨房墙壁都弄得满是果汁!更糟糕的是,保修不包括清理厨房的费用。伙计,我现在需要你的帮助!
LangChain : 对话 API
上面是使用 OpenAI 原始的 SDK 完成上述任务需要将不同信息以及不同的指令组装真一个完整的 Prompt,然后将其传递给模型。如果我们需要的封装的信息很多,上述拼接的过程将会变得繁琐,并且会成为胶水代码。另外就是,Prompt 的构建必须在所有的信息都准备完成之后,才能定义 Prompt 的字段。
下面我们就看一下使用 LangChain 怎么完成上述的任务。
# 下载 langchain 依赖
# langchain 版本迭代速度很快,目前示例代码是基于 0.0.188 版本开发,其他版本可能会导致一些代码无法运行。
%pip install --upgrade langchain==0.0.188
模型:Model
这里的模型指的就是大语言模型(LLM),可以根据输入的 Prompt 进行推理,并给出对应的结果。LangChain 封装多个 LLM 的实现, OpenAI 就是其中的一个。下面看一下如何通过 LangChain 来访问 OpenAI 的功能,封装的模型为 ChatOpenAI ,使用前需要先导包。
# 导包 ChatOpenAI
from langchain.chat_models import ChatOpenAI
# 有很多参数(是gpt-3.5还是gpt-4等等)可以设置,这里以 temperature 参数为例
chat = ChatOpenAI(temperature=0.0)
print(chat)
verbose=False callbacks=None callback_manager=None client=<class 'openai.api_resources.chat_completion.ChatCompletion'> model_name='gpt-3.5-turbo' temperature=0.0 model_kwargs={} openai_api_key=None openai_api_base=None openai_organization=None openai_proxy=None request_timeout=None max_retries=6 streaming=False n=1 max_tokens=None
提示词模版:Prompt template
翻译邮件
在 OpenAI 原始接口的部分,我们需要把所有的信息组装成一个最终的 Prompt 进行使用,在 LangChain 中对这部分也进行了封装,是其使用起来更加方便。
首先我们定义一个 template_string Prompt,其包含两个带输入的信息:style 和 text ,与上面的信息基本一致,然后通过这个字符串可以构建出一个 PromptTemplate 类,我们可以通过这个类可以做到一些更灵活的事情,代码大致如下:
from langchain.prompts import ChatPromptTemplate, HumanMessagePromptTemplate
# 定义 Prompt
template_string = """Translate the text
that is delimited by triple backticks
into a style that is {style}.
text: ```{text}```
"""
# 备注:应该是视频中使用的 LangChain 版本与我本地使用的版本(0.0.188)不同,导致 API 报错
# 已使用 HumanMessagePromptTemplate 替换 ChatPromptTemplate 的部分用法;
# 原始写法如下:
# prompt_template = ChatPromptTemplate.from_messages(template_string)
human_prompt_template = HumanMessagePromptTemplate.from_template(template_string)
prompt_template = ChatPromptTemplate.from_messages([human_prompt_template])
# 打印构建出的 Prompt 的完整内容
prompt = prompt_template.messages[0].prompt
print(prompt)
# 打印构建出的 Prompt 包含需要替换的属性
print(prompt.input_variables)
input_variables=['style', 'text'] output_parser=None partial_variables={} template='Translate the text that is delimited by triple backticks into a style that is {style}. text: ```{text}```n' template_format='f-string' validate_template=True
['style', 'text']
好的,下面我们补全缺少的 style 和 text 信息,并通过 ChatPromptTemplate 中的 format_messages 函数将其传入,大致代码如下:
# style
customer_style = "Simplified Chinese, in a calm/friendly/formal/respectful tone"
# text
customer_email = """
Arrr, I be fuming that me blender lid
flew off and splattered me kitchen walls
with smoothie! And to make matters worse,
the warranty don't cover the cost of
cleaning up me kitchen. I need yer help
right now, matey!
"""
# 传入对应的 style 和 text 信息
customer_messages = prompt_template.format_messages(
style=customer_style,
text=customer_email)
# 查看输出
print(customer_messages[0])
content="Translate the text that is delimited by triple backticks into a style that is Simplified Chinese, in a calm/friendly/formal/respectful tone. text: ```nArrr, I be fuming that me blender lid flew off and splattered me kitchen walls with smoothie! And to make matters worse, the warranty don't cover the cost of cleaning up me kitchen. I need yer help right now, matey!n```n" additional_kwargs={} example=False
根据输出可以看出,上面缺少的信息已经补充完整,customer_messages 已经是一个完整的 Prompt 了。下面把这个完整的 Prompt 输入到 ChatOpenAI 中,查看其返回情况:
# Call the LLM to translate to the style of the customer message
customer_response = chat(customer_messages)
print(customer_response.content)
嗨,我很生气,我的搅拌机盖子飞了出去,把我的厨房墙壁都弄得满是果汁!更糟糕的是,保修不包括清理厨房的费用。伙计,我现在需要你的帮助!
回复邮件
上述使用 LangChain 完成翻译润色客户邮件的场景,下面我们就看一下如何使用同样的方式来回复用户的邮件。
我们使用中文编写对应的回复邮件,需要将其翻译成目标语言(这里是英文)并且需要去除一些口语化的表达,下面是回复的内容以及对应的 Prompt。
# 回复内容
service_reply = """额,保修不包括你的厨房的清洁费用,
因为你使用搅拌机的时候忘记盖上盖子了,这是你操作的失误,这是你的问题。真倒霉!再见!
"""
# 要求
service_style_pirate = """
a polite tone
that speaks in English Pirate
"""
# 组装 prompt
service_messages = prompt_template.format_messages(
style=service_style_pirate,
text=service_reply)
# 打印&检查 prompt
print(service_messages[0].content)
Translate the text that is delimited by triple backticks into a style that is a polite tone that speaks in English Pirate. text: ```额,保修不包括你的厨房的清洁费用,
因为你使用搅拌机的时候忘记盖上盖子了,这是你操作的失误,这是你的问题。真倒霉!再见!
```
# 生成对应的回复邮件文本
service_response = chat(service_messages)
print(service_response.content)
Arrr, me hearty! Beggin' yer pardon, but the warranty don't be coverin' the cost o' cleanin' yer galley, as ye forgot to put the lid on yer blender, which be a mistake on yer part. 'Tis yer own problem, matey. Aye, tough luck! Farewell!
prompt template 的优势
可以看出 prompt_template 是对我们自己的 Prompt 做了一层封装,是其使用起来比较方便,在复杂应用开发时也可以很好的复用这些逻辑。
除此之外,LangChain 中的 prompt template 还提供了一些其他的功能:
- 内置了多种 Prompt(如文本总结/QA/SQL/API调用等),不用我们自己再调试最佳的 Prompt;
- 支持输出解析(Output Parsers),将 LLM 的结果以结构化(如 JSON)的方式返回;
- 内置了思维链,使 LLM 的回答更加合理;
输出解析器:Output Parsers
下面我们介绍下输出解析(Output Parsers)的使用场景。假如我们现在有到一些商品的评价,想要对这些评价做一些处理从而可以更好的分析数据。比如,我们期望可以根据输入用户的商品评价,输出对应的 JOSN 数据,包含以下字段信息:
- gift:是否是把商品当作礼物, bool 类型;
- delivery_days:商品配送时间,没有的话返回 -1 ;
- price_value:提起有关价格相关的信息,返回一个列表;
我们期望 LLM 返回下面的 JSON 格式:
{
"gift": False,
"delivery_days": 5,
"price_value": "pretty affordable!"
}
{'gift': False, 'delivery_days': 5, 'price_value': 'pretty affordable!'}
下面是从京东上随机挑选的一个 MacBook Pro 的评价,以及对应的 Prompt 信息。
# 用户的商品评价
customer_review = """
MacBook Pro特别棒!特别喜欢!m2处理器性能超强,就是价钱有点小贵!电池续航逆天!不发热!还带有黑科技触控栏!
现在Mac 软件还算蛮多的,常用的办公软件都能有!用来日常办公完全没问题!
我想重点点评一下他的音频接口!这代MacBook Pro 带有先进的高阻抗耳机支持功能!同样的耳机,
插MacBook Pro上,效果要好于iPhone!还有它的录音性能!插上一根简单的转接头后,在配合电容麦,
还有库乐队软件,录音效果逆天!真的特别棒!我有比较老版本的Mac,但这代MacBook Pro的录音效果,
真的比以前的Mac效果要好好多倍!特别逆天!适合音乐人!(个人感觉,不插电源,录音效果似乎会更好!)
"""
# Prompt 编写
review_template = """
For the following text, extract the following information:
gift: Was the item purchased as a gift for someone else?
Answer True if yes, False if not or unknown.
delivery_days: How many days did it take for the product
to arrive? If this information is not found, output -1.
price_value: Extract any sentences about the value or price,
and output them as a comma separated Python list.
Format the output as JSON with the following keys:
gift
delivery_days
price_value
text: {text}
"""
下面是具体的请求逻辑:
from langchain.prompts import ChatPromptTemplate
# 创建 ChatPromptTemplate
prompt_template = ChatPromptTemplate.from_template(review_template)
messages = prompt_template.format_messages(text=customer_review)
print(messages)
# 创建 LLM
chat = ChatOpenAI(temperature=0.0)
# 请求
response = chat(messages)
print(response.content)
[HumanMessage(content='For the following text, extract the following information:nngift: Was the item purchased as a gift for someone else? Answer True if yes, False if not or unknown.nndelivery_days: How many days did it take for the product to arrive? If this information is not found, output -1.nnprice_value: Extract any sentences about the value or price,and output them as a comma separated Python list.nnFormat the output as JSON with the following keys:ngiftndelivery_daysnprice_valuenntext: nMacBook Pro特别棒!特别喜欢!m2处理器性能超强,就是价钱有点小贵!电池续航逆天!不发热!还带有黑科技触控栏!n现在Mac 软件还算蛮多的,常用的办公软件都能有!用来日常办公完全没问题!n我想重点点评一下他的音频接口!这代MacBook Pro 带有先进的高阻抗耳机支持功能!同样的耳机,n插MacBook Pro上,效果要好于iPhone!还有它的录音性能!插上一根简单的转接头后,在配合电容麦,n还有库乐队软件,录音效果逆天!真的特别棒!我有比较老版本的Mac,但这代MacBook Pro的录音效果,n真的比以前的Mac效果要好好多倍!特别逆天!适合音乐人!(个人感觉,不插电源,录音效果似乎会更好!)nn', additional_kwargs={}, example=False)]
{
"gift": false,
"delivery_days": -1,
"price_value": ["就是价钱有点小贵!"]
}
可以看出 response 返回结果基本和我们预期的一致,但是这个时候我们并不能直接操纵这个 JOSN,目前他还只是一个字符串,比如下面的代码会报错。
# 下面的代码会报错,因为 content 并不是字典,而是一个字符串
response.content.get('gift')
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[58], line 5
1 # You will get an error by running this line of code
2 # because'gift' is not a dictionary
3 # 'gift' is a bool
4 response.content
----> 5 response.content.get('gift')
AttributeError: 'str' object has no attribute 'get'
Parse the LLM output string into a Python dictionary
解决上面的报错,就需要用到 LangChain 的数据解析功能了。首先我们需要导入 ResponseSchema 和 StructuredOutputParser,代码如下:
from langchain.output_parsers import ResponseSchema
from langchain.output_parsers import StructuredOutputParser
# 对每个期望返回的内容做一个详细的描述,确保 LLM 知道你的意图
gift_schema = ResponseSchema(name="gift",
description="Was the item purchased as a gift for someone else? Answer True if yes,False if not or unknown.")
delivery_days_schema = ResponseSchema(name="delivery_days",
description="How many days did it take for the product to arrive? If this information is not found, output -1.")
price_value_schema = ResponseSchema(name="price_value",
description="Extract any sentences about the value or price, and output them as a comma separated Python list.")
# 以字典的方式构建 schema
response_schemas = [gift_schema,
delivery_days_schema,
price_value_schema]
# 创建 OutputParser
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
# 生成对应的指令,这里会做为 Prompt 内容的一部分
format_instructions = output_parser.get_format_instructions()
print(format_instructions)
The output should be a markdown code snippet formatted in the following schema, including the leading and trailing "```json" and "```":
```json
{
"gift": string // Was the item purchased as a gift for someone else? Answer True if yes,False if not or unknown.
"delivery_days": string // How many days did it take for the product to arrive? If this information is not found, output -1.
"price_value": string // Extract any sentences about the value or price, and output them as a comma separated Python list.
}
```
下面就是将 format_instructions 内容与 Prompt 整合在一起了,并且生成最终的 Prompt 信息。
review_template_2 = """
For the following text, extract the following information:
gift: Was the item purchased as a gift for someone else?
Answer True if yes, False if not or unknown.
delivery_days: How many days did it take for the product
to arrive? If this information is not found, output -1.
price_value: Extract any sentences about the value or price,
and output them as a comma separated Python list.
text: {text}
{format_instructions}
"""
human_prompt_template = HumanMessagePromptTemplate.from_template(review_template_2)
prompt = ChatPromptTemplate.from_messages([human_prompt_template])
messages = prompt.format_messages(text=customer_review, format_instructions=format_instructions)
print(messages[0].content)
For the following text, extract the following information:
gift: Was the item purchased as a gift for someone else? Answer True if yes, False if not or unknown.
delivery_days: How many days did it take for the productto arrive? If this information is not found, output -1.
price_value: Extract any sentences about the value or price,and output them as a comma separated Python list.
text:
MacBook Pro特别棒!特别喜欢!m2处理器性能超强,就是价钱有点小贵!电池续航逆天!不发热!还带有黑科技触控栏!
现在Mac 软件还算蛮多的,常用的办公软件都能有!用来日常办公完全没问题!
我想重点点评一下他的音频接口!这代MacBook Pro 带有先进的高阻抗耳机支持功能!同样的耳机,
插MacBook Pro上,效果要好于iPhone!还有它的录音性能!插上一根简单的转接头后,在配合电容麦,
还有库乐队软件,录音效果逆天!真的特别棒!我有比较老版本的Mac,但这代MacBook Pro的录音效果,
真的比以前的Mac效果要好好多倍!特别逆天!适合音乐人!(个人感觉,不插电源,录音效果似乎会更好!)
The output should be a markdown code snippet formatted in the following schema, including the leading and trailing "```json" and "```":
```json
{
"gift": string // Was the item purchased as a gift for someone else? Answer True if yes,False if not or unknown.
"delivery_days": string // How many days did it take for the product to arrive? If this information is not found, output -1.
"price_value": string // Extract any sentences about the value or price, and output them as a comma separated Python list.
}
```
我们请求 LLM 并查看其返回的信息,
# 请求 LLM
response = chat(messages)
# 将结果解析成对应的字典
output_dict = output_parser.parse(response.content)
print(output_dict.get('price_value'))
['就是价钱有点小贵!']
小结
本节课程带你体验了使用 OpenAI SDK 进行对话的简单,在这个过程中会存在一些胶水代码。这个问题在小项目中并不是什么问题,但是在大型项目中却是不能忽视的工程问题,为了解决上述问题我们引入了 LangChain 这个库,他会把整个对话的流程封装起来,根据容易扩展:
- 在 Prompt 输入方面,除了使用灵活之外还提供了各种场景的最佳 Prompt 写法;
- 在 Model 方面,提供了一些默认的 OpenAI 请求参数,同时如果后期替换成其他的 LLM 模型也会比较方便;
- 在 LLM 数据处理方便,可以使用 Output Parsers 很好的将结果处理成字典格式,方便后续的进一步操作;
好的,下一节我们将讲解 LangChain 的记忆(memory)能力。
